
오차 역전파 알아보기
오차 역전파
오차 역전파란 무엇일까?
퍼셉트론으로 해결되지 않던 문제를 신경망을 이용해 해결할 수 있게 되었다.
이 신경망 내부의 가중치를 수정하는 방법이 오차 역전파이다.
딥러닝 모델의 학습은 순전파와 역전파로 구성되는데,
이 중 역전파는 신경망이 예측한 결과와 실제 결과 사이의 오차를 신경망에 역으로 전파하는 방법이다.
경사하강법(Gradient Descent)
최적의 가중치와 바이어스를 찾기 위해 경사하강법을 이용한다.
임의의 가중치를 선언하고 결괏값을 이용해 오차를 구한 뒤, 이 오차가 최소인 지점으로 계속해서 조금씩 이동시킨다.
오차가 최소가 되는 점(미분값이 0인 지점)을 찾으면 그것이 우리가 찾고자 하는 값이다!
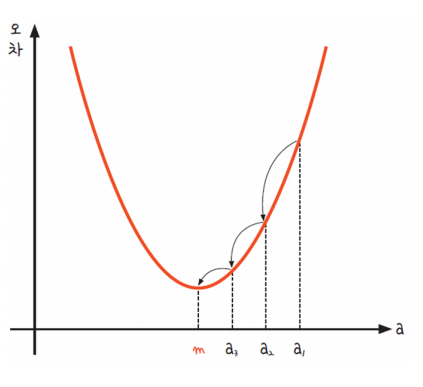
경사 하강법의 과정을 알아보자.
- a1에서 미분을 구한다.
- 구한 기울기의 반대방향(기울기가 +면 음의 방향, -면 양의 방향)으로 이동시킨 a2에서 미분을 구한다.
- 앞에서 구한 미분값이 0이 아니면 1과 2의 과정을 반복한다.

3가지 종류의 경사 하강법
1. 배치 경사 하강법(Batch Gradient Descent)
- 전체 데이터셋에 대한 오류를 구한 후 기울기를 한 번만 계산하며 파라미터를 업데이트.
- 전체 훈련 데이터셋에 대해 가중치를 편미분하는 방법
- 한 스텝에 모든 훈련 데이터셋을 사용하므로 학습이 오래 걸리는 단점이 있음.
2. 확률적 경사 하강법 (Stochastic Gradient Descent)
- 배치 경사 하강법이 모델 학습 시 많은 시간과 메모리가 필요하다는 점을 개선한 방법이 확률적 경사 하강법.
- 배치 사이즈를 1로 설정해 파라미터를 업데이트함.
- 비교적 빠르고 적은 메모리로 학습 가능

3. 미니 배치 경사 하강법(Mini-Batch Gradient Descent)
- Batch Size가 1도 아니고 전체 데이터 개수도 아닌 경우.
- 배치 경사 하강법보다 학습 속도가 빠르고, 확률적 경사 하강법보다 안정적임 -> 현재 딥러닝 분야에서 가장 많이 사용하는 경사 하강법!
- Batch Size는 일반적으로 2의 n제곱으로 지정함
학습률이란?
위에서 설명한 경사 하강법의 과정 2에서 어느정도 이동할 것인지 결정하는 변수이다.
학습률이 크면 많이 이동하고, 작으면 적게 이동한다.
- 구한 기울기의 반대방향(기울기가 +면 음의 방향, -면 양의 방향)으로 이동시킨 a2에서 미분을 구한다.
실제로 딥러닝 모델을 만들 때 적절한 학습률을 찾는 것이 중요하다!
옵티마이저
확률적 경사 하강법의 파라미터 변경 폭이 불안정한 문제를 해결하기 위해 학습 속도와 운동량을 조정하는 옵티마이저를 적용한다.
손실의 최소화와 안정적인 수렴을 위한 것이다.
현재 가장 보편적으로 사용되며, 성능이 우수한 옵티마이저는 Adam이다.
Adam
- 그래디언트의 제곱근 평균과 모멘텀의 추정치를 기반으로 가중치의 업데이트에 사용되는 학습률을 자동으로 조정한다.
- 이로 인해 다른 최적화 알고리즘에 비해 초기 학습률 설정에 덜 민감하다.
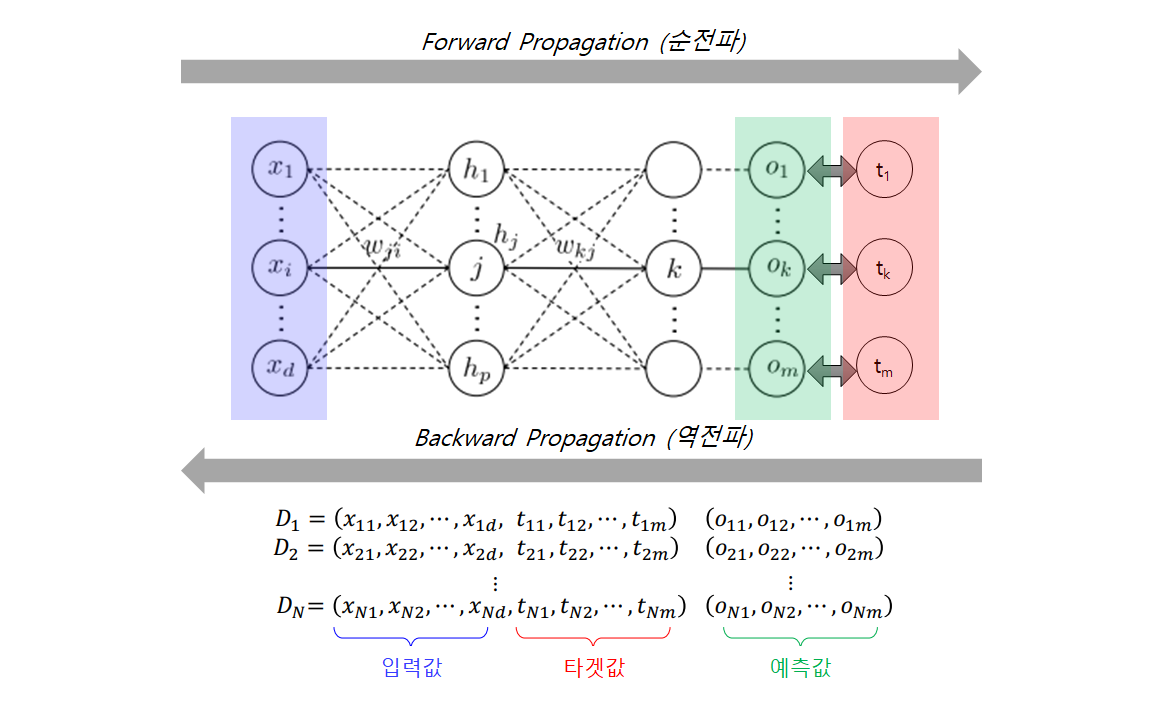
이제 본격적으로 다층 퍼셉트론의 학습 과정을 살펴보자.
학습 과정은 순전파와 역전파로 나뉜다.
1. 순전파
- 1) 입력 데이터는 네트워크의 입력층으로 전달되어 첫 번쨰 은닉층으로 보내짐
- 2) 해당 층에 있는 모든 뉴런의 출력을 계산하고 결과를 다음 층에 전달
- 3) 단계 2를 마지막 출력층의 출력을 계산할 때까지 반복
2. 역전파
- 1) 오차 계산
- 출력층에서의 예측 결과와 실제 정답값 사이의 오차를 계산
- 손실함수를 통해 계산됨
- 2) 계산된 오차에 각 출력 연결이 기여하는 정도를 계산
- 각 레이어의 가중치에 대한 오차의 미분값을 계산
- 연쇄 법칙(chain rule)을 적용해 이전 층의 가중치가 오차에 기여하는 정도를 계산
- 예측 결과에 대해 입력층까지의 오차 그래디언트를 계산
- 3) 경사하강법을 사용해 오차 그래디언트를 이용해서 네트워크의 가중치를 업데이트(수정)
2-1) 에서 오차를 계산하는 방법에 대해서 조금 더 자세하게 알아보자.
이 단계에서는 손실함수를 사용해서 정답과 예측 간의 오차를 계산하고, 가중치를 변경한다.
손실함수는 모델이 나타내는 확률 분포와 데이터가 따르는 실제 확률 분포 사이의 차이를 나타내는 함수이다.
따라서 손실함수의 값이 0에 가까울수록 모델의 정확도가 높은 것이다.
대표적인 손실함수로는 선형 회귀의 경우 평균 제곱 오차 손실(MSE loss),
로지스틱 회귀의 경우 교차 엔트로피 손실이 있다.
이렇게 네트워크의 파라미터(가중치)값을 변경하는 과정을 Fine Tuning(미세조정)이라고 하는데, 적절한 가중치를 얻는 과정 자체가 딥러닝이라고 할 수 있다.
그렇다면 평균 제곱 오차 손실과 교차 엔트로피 손실이 무엇일까 ??
1. 평균 제곱 오차 손실(Means Squared Error loss, MSE)
- 예측한 데이터 값과 실제 값 사이의 평균 제곱 오차
- 데어터가 예측으로부터 얼마나 퍼져있는지 나타낸 손실함수.
- MSE 공식

n = 샘플의 수, y_i = 실제 정답 값, t_i = 예측값
2. 교차 엔트로피 손실(Cross-entropy loss/error, CEE)
- 실제값과 예측값 사이의 차이를 계산하는 데 사용됨.
- 예측한 확률 분포와 실제 분포 사이의 차이를 최소화하려는 목적을 가진 손실함수
- Cross entropy: 예측 분포가 실제 분포에 대해 얼마나 잘 맞는지 측정
- CEE 공식

- cee : 교차 엔트로피 오차
- i : 데이터의 인덱스
- t_i : 실제값 (참값)
- y_i : 모델의 예측값 (출력값)
- Pytorch에서 Cross Entropy의 종류: BCELoss(), CrossEntropyLoss() …
위에서 언급한 Pytorch에서 자주 쓰이는 2개의 Cross Entropy 함수에 대해 알아보자.
BCELoss()
- 이진 분류 문제의 손실을 구할 때만 사용. ex) 강아지 or 고양이
- 출력 레이어에서 하나의 뉴런을 사용하고 주로 sigmoid함수를 활성화 함수로 사용
- BCE 공식
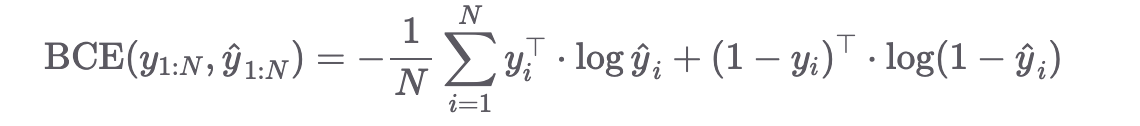
CrossEntropyLoss()
- 다중 분류(Multiclass classification)문제의 손실을 구할 때 사용(2개 이상의 class를 가진 경우)
- 출력 레이어에서 각 클래스마다 하나의 뉴런을 사용하고 주로 softmax함수를 활성화 함수로 사용함.
지금까지 오차 역전파의 개념과 역전파의 과정을 이해하기 위해 필요한 요소들에 대해 살펴보았다.
다음 포스팅에서는 오차 역전파를 직접 계산해보도록 하겠다!